图像分类模型VGG
简介
VGG于2014年由牛津大学科学工程系Visual Geometry Group组提出的。主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者除了网络深度不一样,其本质并没有什么区别。
VGG的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
VGG模型以较深的网络结构,较小的卷积核和池化采样域,使得其能够在获得更多图像特征的同时控制参数的个数,避免过多的计算量以及过于复杂的结构。
特点:小卷积核和多卷积子层
VGG使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。
卷积核的大小影响到了参数量,感受野,前者关系到训练的难易以及是否方便部署到移动端等,后者关系到参数的更新、特征图的大小、特征是否提取的足够多、模型的复杂程度。
VGG用较深的网络结构和较小的卷积核既可以保证感受视野,又能够减少卷积层的参数,比如两个3x3的卷积层叠加等价于一个5x5卷积核的效果,3个3x3卷积核叠加相加相当于一个7x7的卷积核,而且参数更少。这样可以增加非线性映射,也能很好地减少参数,而且三个卷积层的叠加,对特征学习能力更强。
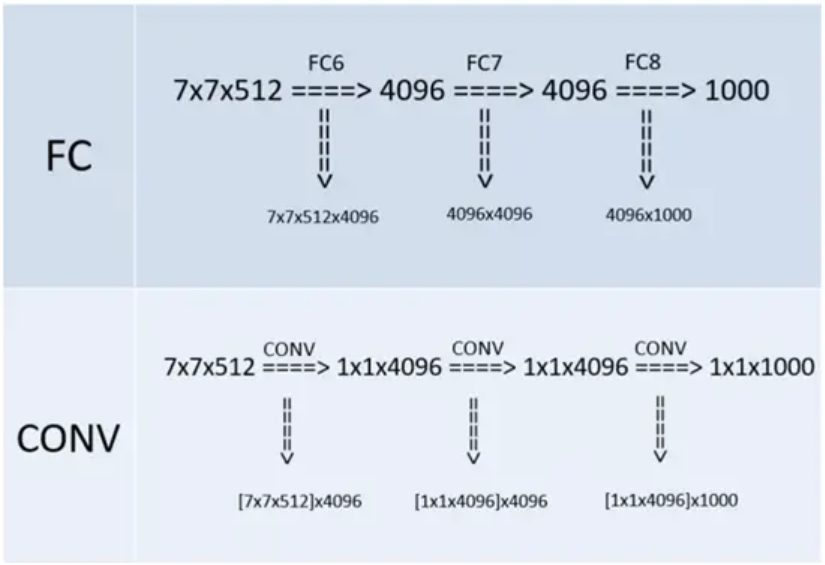
特点:全连接转卷积
在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。
如输入图像是224x224x3,若后面三个层都是全连接,那么在测试阶段就只能将测试的图像全部都要缩放大小到224x224x3,才能符合后面全连接层的输入数量要求,这样就不便于测试工作的开展。
而“全连接转卷积”,替换过程如下:
VGG网络结构
下面是VGG网络的结构,VGG16包含了16个隐藏层(13个卷积层和3个全连接层),如下图中的D列所示,而VGG19包含了19个隐藏层(16个卷积层和3个全连接层),如下图中的E列所示:
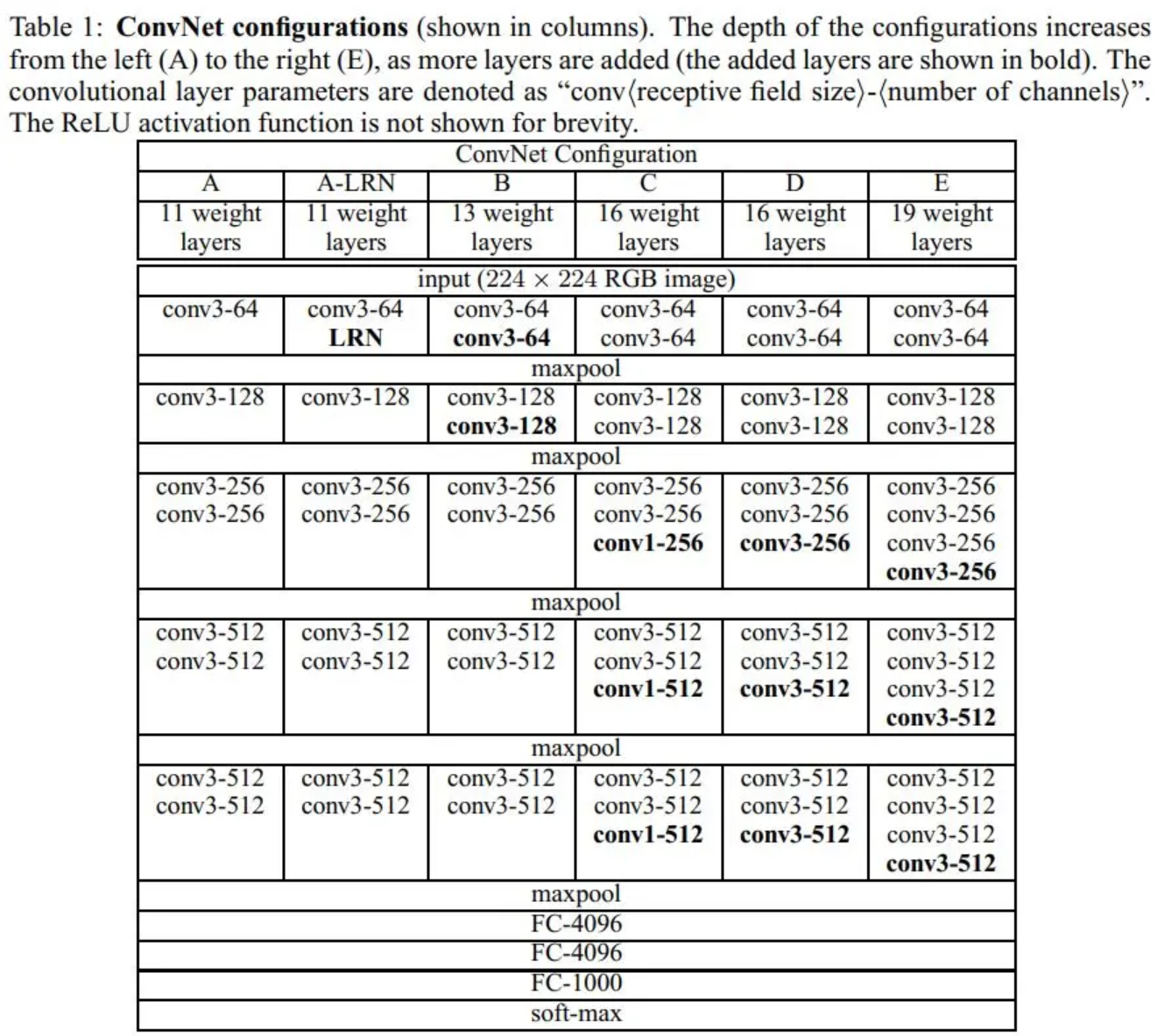
从图中可以看出,VGG网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的max pooling。该模型可以简单分为5个 stage,每层两卷积核池化组成,最后接3层全连接用于分类。 作者表明,虽然两个级联的3x3 conv或三个级联的3x3 conv分别在理论上等价于一个5x5 conv及一个7x7 conv。不过它们所具的模型参数则分别要少于后两者的数目。同时作者实验表明更深(层数更多)而非更宽(conv channels更多)的网络有着自动规则自己参数的能力,因此有着更好的学习能力。
优点
VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)
几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层效果更好
验证了通过不断加深网络结构可以提升性能
适用领域
图像识别(用于类别较多图像识别如猫狗识别、人脸识别),图像风格换等。
在2014年在ILSVRC大赛上获得了分类(classification)项目的第二名和定位(localization)项目的第一名
参考文献
@article{2014Very,
title={Very Deep Convolutional Networks for Large-Scale Image Recognition},
author={ Simonyan, K. and Zisserman, A. },
journal={Computer Science},
year={2014},
}