# 图像分类模型ResNeXt
>[Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/abs/1611.05431)
## 简介
ResNeXt是ResNet和Inception的结合体,ResNext不需要人工设计复杂的Inception结构细节,而是每一个分支都采用相同的拓扑结构。
如果要提高模型的准确率,传统的方法是加深或加宽网络,但随着超参数数量的增加(比如channels数,filter size等等),网络设计的难度和计算开销也会增加。ResNeXt结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量。ResNeXt同时采用VGG堆叠的思想和Inception的split-transform-merge思想,可扩展性比Inception强,可以认为是在增加准确率的同时基本不改变或降低模型的复杂度。
ResNeXt的本质是分组卷积(Group Convolution,通过变量基数(Cardinality)来控制组的数量。分组卷积是普通卷积和深度可分离卷积的一个折中方案,即每个分支产生的Feature Map的通道数为n(n>1)。
## 特点:block单元
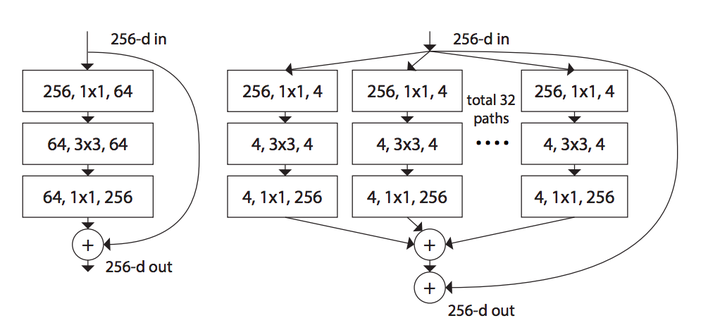
如下图,左边是ResNet的基本结构,右边是构成ResNeXt网络的基本block单元:
图中的每个方框代表一层,三个数据的意义分别为输入数据的channel、fliter大小以及输出数据的channel。
构成ResNeXt网络的基本block单元看起来与Inception Resnet中所有的基本单元极为相似,但是实际上block当中的每个sub branch都是相同的,也就是说**每个被聚合的拓扑结构都是一样的**,这是它与IR网络结构的本质区别,而正是基于这区别,我们可以使用分组卷积来对其进行良好实现。这样就能够使ResNeXt在保证FLOPs和参数量的前提下,通过更宽或更深的网络来提高精度。
## ResNeXt网络结构
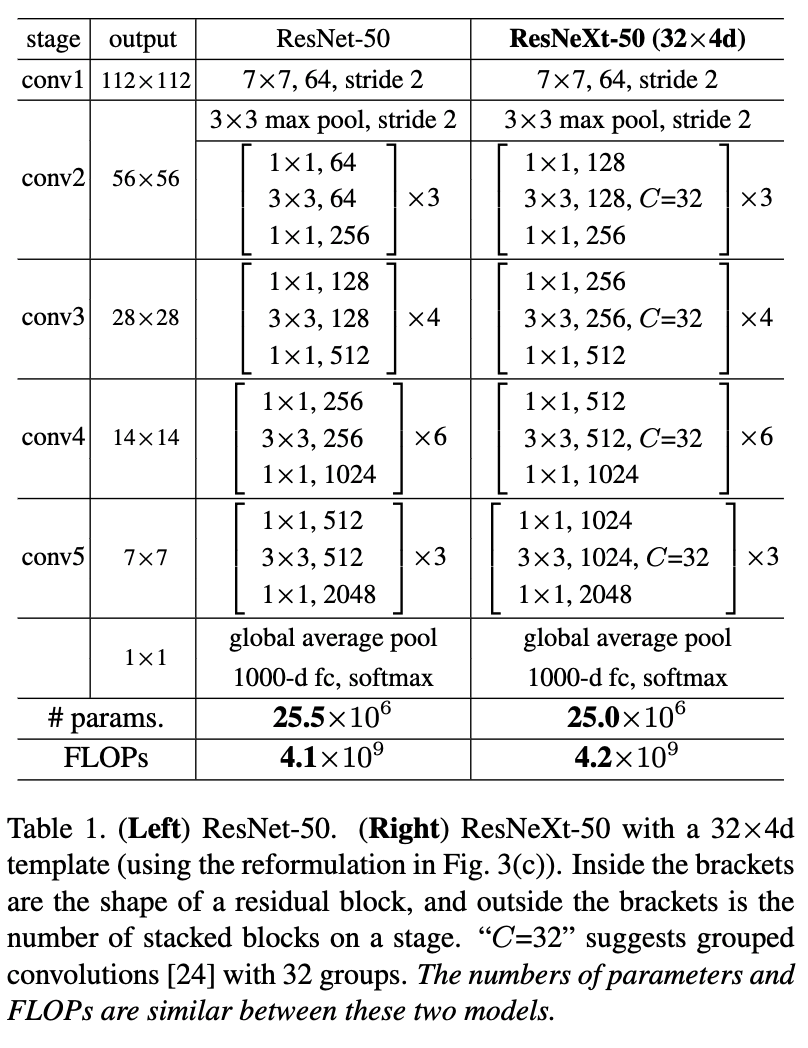
下图中,左边为ResNet-50的网络结构,右边为ResNeXt-50的网络结构:
ResNeXt的网络结构与ResNet类似,选择了简单的基本结构,每一组的C个不同的分支都进行相同的简单变换。上图的ResNeXt-50(32x4d)配置清单中,32指进入网络的第一个ResNeXt基本结构的分组数量C(即基数)为32,4d表示depth(每一个分组的通道数)为4,所以第一个基本结构输入通道数为128。
可以看出,ResNet-50和ResNeXt-50(32x4d)拥有相同的参数,但是精度却更高。在具体实现上,因为1x1卷积可以合并,合并后的代码更简单并且效率更高。虽然两种模型的参数量相同,但是因为ResNeXt是分组卷积,多个分支单独进行处理,所以相较于ResNet整个一起卷积,硬件执行效率上会低一点,训练ResNeXt的每个batch的时间要更长。
## 优点
- ResNeXt的网络结构更简单,可以防止对于特定数据集的过拟合,在用于自己的任务的时候,自定义和修改起来更简单
- 引入了cardinality的概念,能更好的学到特征信息的不同,从而达到更好的分类效果
## 参考文献
~~~
@article{2016Aggregated,
title={Aggregated Residual Transformations for Deep Neural Networks},
author={ Xie, S. and Girshick, R. and P Dollár and Tu, Z. and He, K. },
journal={IEEE},
year={2016},
}
~~~